EROFT: Meditation 3
This week I combined selenium web browsing with scraping and NLP to create a wikipedia prophecy generator, or wiki-omancy. When thinking about “-omancy” possibilities I broke down the typical structure – it involves some user input/action, some randomness, and a parsing of the result to give a prediction.
My original inspiration was the process of going to a wikipedia page to look something specific up and then inevitably browsing through a connected series of links until you land on a page that has no resemblance or relationship to the first article. I can do this shit for ages.
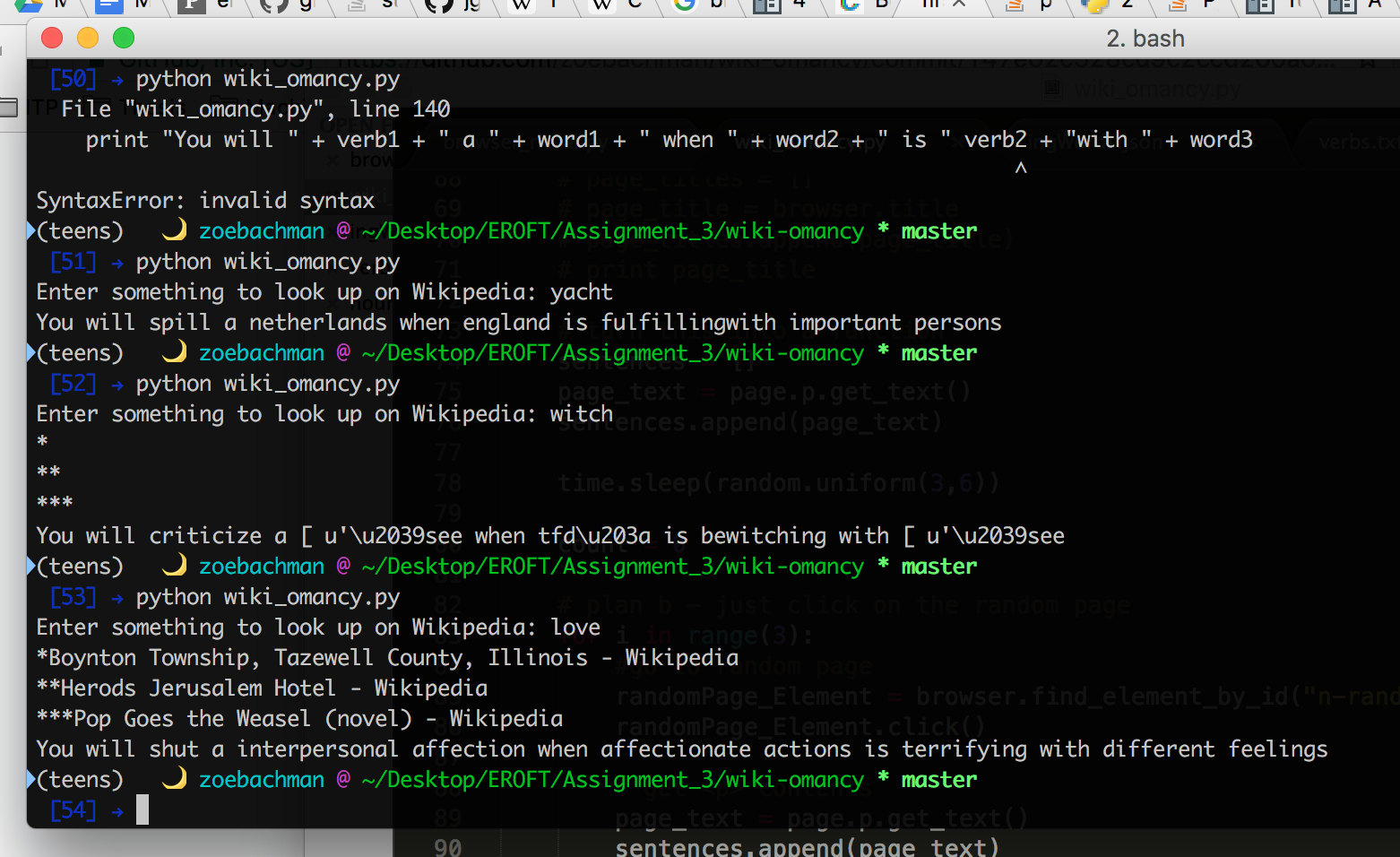
I took some of my code from the first meditation (Selenium) and combined it with code from my second meditation (BeautifulSoup and TextBlob). The program asks the user to input what they’re seeking (in one word). This generates a wikipedia URL, which Selenium brings up and BeautifulSoup scrapes the article contents and stores it in a list.
Now, what I wanted to do was have the page identify all the URLs in the article, select one and go there and repeat the webscraping process. However, I was getting the links with the tags and after wrestling with it for a bit I moved on to plan b (I have those functions commented out in the top part of my code.)
Plan b was to take advantage of the ‘random page’ url that’s on the left nav bar on every wikipedia article page. So, once it goes to the first page based on user input, it generates three random pages and stores their contents as well. Then, the program uses a combination of the stored content with verb lists and some mad-lib style structure to generate a unique prophecy based on the browsing ritual.
Overall, I’m pleased with how it ended up. I would like to debug the article links selection and use that instead of the random article link. I’d also like to do more in the prophecy to get at the patterns and relationships between the random selection, somehow give more meaning to that randomness.
Here’s the code on github: https://github.com/zoebachman/wiki-omancy